Configure datasets
By default, a dataset is created for each of your standard casetypes. For example, if you have created casetypes named Customer, Order, and User, a default dataset is created for each with columns for the casetype attributes and some of the case metadata. If you add more attributes to a casetype, the default dataset is updated automatically. Your Studio also contains a number of default datasets for optional and mandatory tasks.
You can use these default datasets as they are (for example, to display data or populate picklists) or you can use them to create new datasets that filter or aggregate that data. You can also create completely new datasets. This is useful if you want to combine multiple casetypes in a single dataset, join datasets together, import data from outside your application, or access the performance or error logs generated by your application.
Create a new dataset
You can view and update your existing datasets and create new datasets from the Datasets page in your Studio.
To create a new dataset:
- From your Studio, open the Datasets page and click Create dataset.
- Enter a name for the dataset.
- From the Type list, select the type of dataset you want to create. Once you have created a dataset, you cannot change the type.
- Based on multivalue attribute: Identify cases using a multivalue attribute on a case. For example, you can use this to identify all users that have been added to a platform role (using a multivalue attribute on a page casetype).
- Cases: Identify cases from one or more casetypes. You can then apply filters to restrict the dataset to a subset of cases.
When combining multiple casetypes in a dataset, ensure there is a common attribute that you can use to filter the list of cases. - Filter: Identify a subset of items from an existing dataset. You can use this option to create a filtered dataset based on a default casetype dataset. As default datasets are updated automatically when you add new attributes to a casetype, this ensures any new attributes are always available to use in the filtered dataset. For more information, see Filter datasets with conditions.
- Aggregation: Return a count of items in an existing dataset or perform calculations on numerical data in an existing dataset and return the results of those calculations. For more information, see Aggregate data from a dataset.
- Tasks: Create datasets containing details of mandatory or optional tasks that have been added to your application. This can include tasks for which an AI agent has suggested the values for the task.
- JSON array of JSON objects: Create a dataset from an array of JSON objects provided as part of the dataset configuration. For more information, see Provide data from an external source.
- External URL: Import data into a dataset from an API. For more information, see Provide data from an external source.
- Join: Combine data from two existing datasets into a new dataset. For more information, see Join datasets together.
- Casedata history: List the changes that have been made to one or more cases. Each row in the dataset represents a change to a case attribute or a case being created or deleted. To restrict the dataset to a particular case or cases, enter a case ID or an inline template in the Case pointer field.
- Logs: Fetch error or performance logs generated by your application. This information is also available from Developer Tools. Note that you cannot create aggregations based on log datasets.
- To restrict the list of attributes available in the dataset designer to a particular casetype, select the relevant casetype(s) from the Will be executed on casetypes list. If you do not select a casetype, attributes from all casetypes are listed in the designer.
- For datasets containing either cases or case IDs from a multivalue attribute, specify whether open and/or closed (finished) cases should be included. By default, only open cases are included. You can change these settings later by editing the dataset properties.
- To make it possible to query the dataset via Grexx Connect, grant View rights to the role that will be used by the API. You can also change this setting later from the Rights tab. Note that you control which users can see the contents of a dataset by granting rights to the widget or activity that uses the dataset.
- To add columns for case metadata to the dataset automatically, select the metadata you want to include. You can also add (or remove) these columns manually once the dataset has been created using the dataset designer.
- When you are ready, click Create dataset. The dataset designer is displayed.
Once you have created a dataset, the next step is to configure the columns that you want to include.
Configure dataset columns
The dataset columns control the data that is included in the dataset. By adding columns you can include case metadata (such as the case ID), case attributes, task details, and other information as per the dataset type.
To configure the columns in a dataset:
- From the Datasets page, open the dataset and select the Designer tab.
- Either select an existing column or click the column icon to add a new column and then select it to display the column properties.
- Enter a title for the column. The column title is displayed in grid widgets by default.
- Select the Field type according to the source of the data (such as case data, case metadata, or activity metadata). Then select the specific attribute or value that you want to include as appropriate. Note that:
- Selecting Platform attribute is useful if the dataset contains multiple casetypes, all of which use the same platform attribute.
- You can use Activity metadata to include details such as the activity name and ID. These values will be the same for all tasks belonging to that activity.
- You can use Task metadata to include details about the individual task, such as the due date or the date the task was submitted.
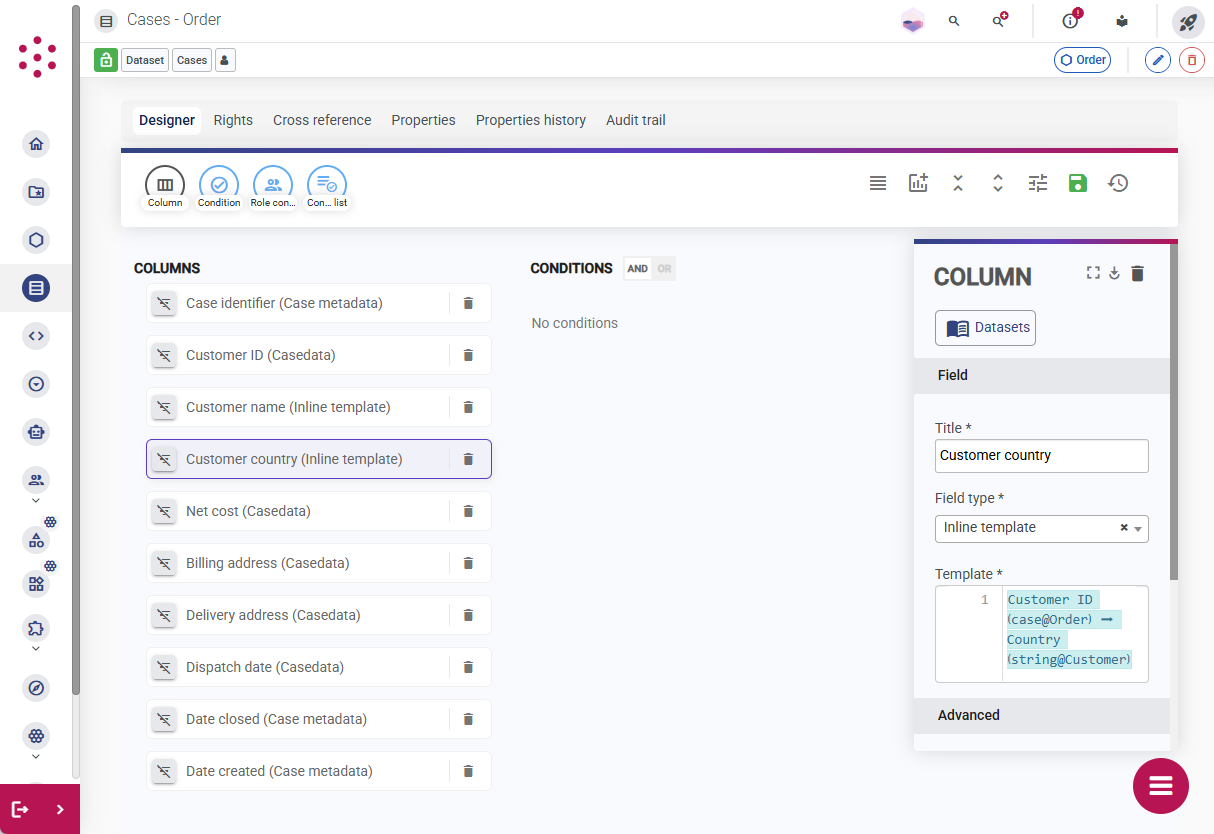
- An Inline template allows you to import details from another case that is related to the listed case. For example, in a dataset containing
Ordercases you might want to include columns containing details from the relatedCustomercase, such as the customer's name or location. You can use an inline template to select an attribute on theOrdercase that contains the case ID for the relatedCustomercase, and use that to link to another attribute on theCustomercase, and pull that data into the dataset. Alternatively, you can use a join dataset to combine data from two different datasets. - You can also use an Inline template to include the label for attribute values selected from a picklist, instead of the stored value. This can be useful if you want to sort or filter the dataset using the label rather than the value. Use the template to select the case attribute, and then click the blue text and enable Use picklist label. Note:
- For static picklist items, you specify both the label and the value to store when you configure the item.
- For picklists based on a dataset, the label is usually made up of one or more attribute values, while the stored value is the case ID or task ID.
- You can specify an external reference so that you can query the values in a dataset using an API, plugin, or the Dataset to JSON or Dataset to Excel system services. For columns that contain attributes, any external reference that you have specified on the attribute is inherited by default. You can override the default value by entering a different value in the External reference field, or enable Override External reference with empty to replace the default value with no value.
If you have created a filtered dataset, the columns are defined by the parent dataset. For information about adding columns to aggregation datasets, see Create an aggregated dataset.
Combine multiple casetypes in a dataset
When you create a new dataset and set the type to Cases, you can select more than one casetype. This is useful if your application contains several related casetypes with some common attributes.
For example, in an HR application you might have different casetypes for Employee and Contractor (perhaps because the activities relating to each are different). In that situation, you may want to include both Employee and Contractor cases in a single list so that users can search across all staff members. You can do this by creating a dataset that contains both casetypes.
When you combine multiple casetypes in a dataset, you can include columns to display attributes from each casetype (as well as case metadata that is common to all casetypes). By default, attribute columns only contain data for the casetypes to which they belong. For example, if you have added a Last name attribute to both the Employee and Contractor casetypes, the column for the attribute on the Employee casetype will only contain data for Employee cases. To display the Last name data for Contractor cases, you would need to add the attribute for that casetype as a separate column.
However, if you have used platform attributes for attributes that are common to multiple casetypes, you can use these to include details from different casetypes in the same column. For example, if you have configured Last name as a platform attribute and applied this to both the Employee and Contractor casetypes, you can add a single Last name column to the dataset in order to display details for cases of either type.
You can also use platform attributes to filter the cases included in the dataset. For example, if you have added a Start date platform attribute to both the Employee and Contractor casetypes, you could filter the dataset to include only employees and contractors with a start date before 1 January 2024.
When you include multiple casetypes in a dataset, a new row is created for each case. To combine data from two datasets into the same row, use either an inline template column (as described above) or create a Join dataset. This is useful, for example, if you want to return a row for each Order case and include details from the related Customer case in the same row.
Next steps
Once you have configured a dataset, you may want to add conditions to filter the data that it returns. You can use Developer Tools to test that a dataset returns the data you expect when run in one of your DTAP environments.
You can use datasets to display data, populate a picklist, or identify cases for an activity. For more information, see Use datasets in your application.